
The DIY RAG Pilot Is Dead: A Guide to Production-Grade Enterprise AI
Executive Summary: Your engineering team’s proof-of-concept for Retrieval-Augmented Generation (RAG) is impressive, but it’s a trap. The leap from a simple LangChain script connecting to a vector database to a secure, scalable, and accurate enterprise system is massive and fraught with peril. I’ve seen companies waste millions on RAG pilots that fail under real-world conditions because they treat it as a simple LLM feature, not the complex data pipeline architecture it truly is. This guide introduces the RAG Maturity Model, a framework I use to bridge C-Suite strategy with engineering reality, ensuring your investment yields a defensible competitive advantage, not a costly science project.
The Hook: Why Your RAG Pilot Will Fail at Scale
Your team has successfully built a chatbot that can answer questions from a small set of PDF documents. The demo wowed the executive team. The problem is, this “Naive RAG” approach, which simply chunks documents, embeds them, and performs a similarity search, breaks down completely when faced with the complexity of enterprise data—conflicting sources, access control, and the relentless need for freshness. The path to production requires a radical shift in thinking from “prompt engineering” to “data flow architecture.”

The Business Case: Beyond Q&A Bots
The strategic value of Retrieval-Augmented Generation (RAG) isn’t just deflecting support tickets. It’s about creating a proprietary intelligence layer on top of your unique enterprise data. This unlocks new revenue streams and operational efficiencies that are impossible to replicate with off-the-shelf models. As detailed in a recent Harvard Business Review article on AI strategy, the goal is to build a competitive moat.
- Alpha Generation (Finance): A RAG system ingesting real-time financial news, earnings transcripts, and internal analyst reports can surface insights for portfolio managers faster than any human team.
- Accelerated Drug Discovery (Pharma): Connecting LLMs to decades of research papers, clinical trial data, and genomic databases can identify novel research pathways.
- Hyper-Personalized E-commerce: Moving beyond simple product recommendations to a conversational advisor that understands a customer’s entire purchase history, support interactions, and browsing behavior to provide tailored advice.
However, these outcomes are only possible with a production-grade system. A naive pilot that hallucinates or provides stale information doesn’t just fail; it actively destroys user trust and brand equity. This is a key component of how to use AI in business for competitive advantage.
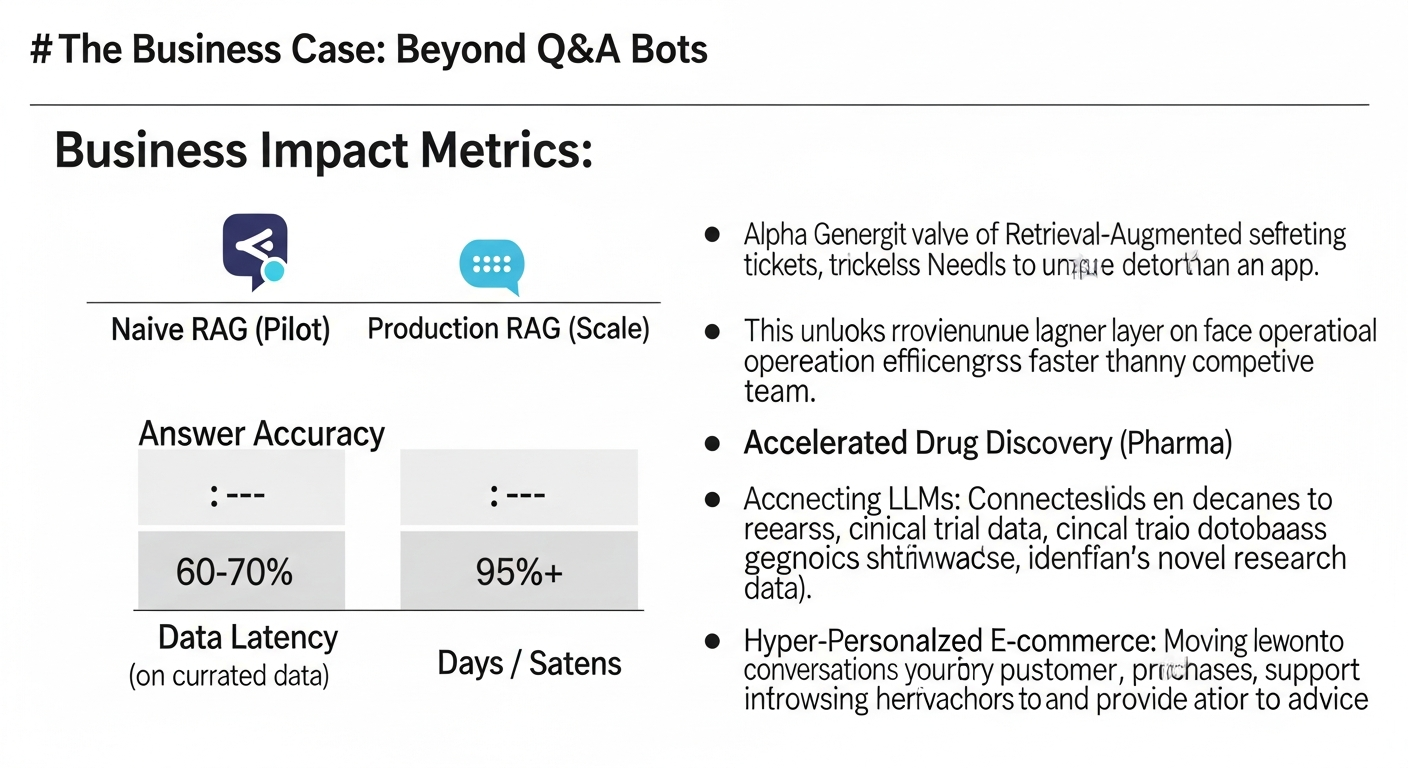
Business Impact Metrics:
| Metric | Naive RAG (Pilot) | Production RAG (Scale) |
| :— | :— | :— |
| Answer Accuracy | 60-70% (on curated data) | 95%+ (on diverse, real-world data) |
| Data Latency | Days / Manual Updates | < 5 Minutes (Real-time ingestion) |
| Cost Per 1k Queries | ~$2.50 | ~$0.80 (with caching & optimization) |
| Security | None / Single Role | Per-document, user-level ACLs |
| ROI (Year 1) | Negative (Cost Center) | 200-400% (Efficiency Gains) |

The Architecture: The RAG Maturity Model
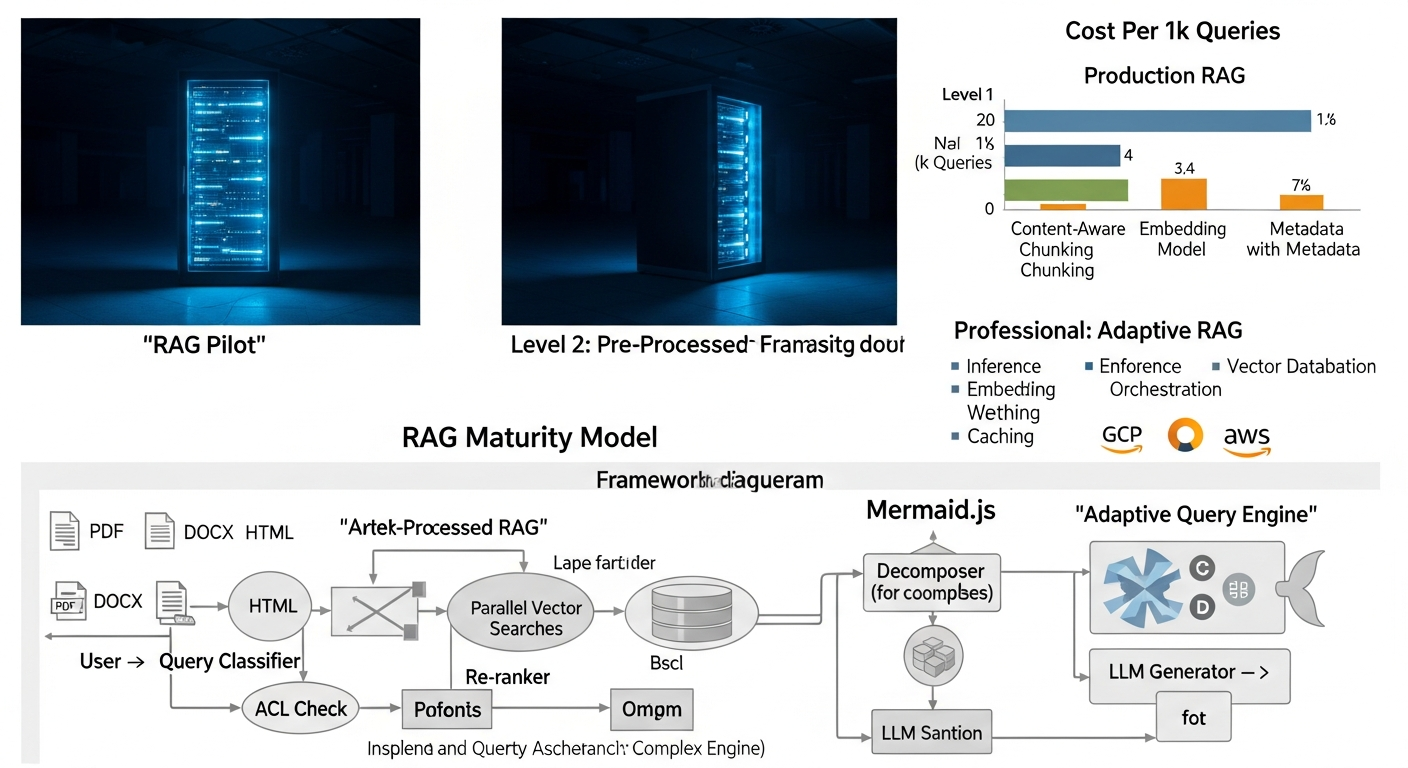
I’ve developed a four-stage maturity model to help organizations diagnose their current state and plot a course to production. Most teams are stuck at Level 1, and the real value—and difficulty—begins at Level 2.

Level 1: Naive RAG (The Demo)
This is the standard tutorial implementation, often explored when first learning what is Generative AI. It works for a single data source and a handful of documents but has critical flaws.
* Process: Fixed-size chunking -> Embedding -> Vector Search -> Synthesize.
* Failure Mode: The “lost in the middle” problem, where crucial information is buried in a large context window. Poor performance on complex documents like tables or multi-column layouts.
Level 2: Pre-Processed RAG (The Foundation)
Here, we treat the ingestion process with the seriousness it deserves. It’s a data engineering problem first, an AI problem second. The goal is to improve the quality of the “retrieval” step before the LLM is ever called.
* Key Additions:
* Content-Aware Chunking: Instead of fixed sizes, we use parsers that understand Markdown headers, HTML tables, or code blocks to create logically coherent chunks.
* Metadata & Indexing: We extract entities, dates, and summaries, storing them as metadata alongside the vector embeddings. This allows for powerful hybrid search as described in Google Cloud’s blog on vector search.
* Re-ranking: The initial vector search might return 20 relevant chunks. A lightweight re-ranking model (like a cross-encoder) re-orders these 20 chunks for relevance before passing the top 3-5 to the expensive LLM.

Level 3: Adaptive RAG (The Production System)
This is where the system becomes dynamic. It learns from user interactions and adapts its own processes to improve performance, moving beyond a simple tech stack to an intelligent system.
* Key Additions:
* Query Transformation: The system analyzes the user’s query. Is it a simple keyword search? A complex question? It might break a complex question into multiple sub-queries or generate hypothetical answers to find better document matches, a technique explored in the original RAG paper from Facebook AI Research.
* Recursive Retrieval & Graph Traversal: For a query like “Compare Project A and Project B,” the system retrieves summary documents for each, then recursively retrieves the specific sub-documents cited in those summaries. This moves from a simple vector search to a graph-based exploration of your knowledge base.
* Feedback Loops: When a user upvotes or downvotes an answer, this feedback is used to fine-tune the re-ranking model or identify problematic document chunks.
Here is what the core logic for an adaptive query engine might look like in pseudo-code.
This is a simplified view, but it highlights the shift from a single API call to an orchestrated workflow.
 Query Classifier -> Decomposer (for complex queries) -> Parallel Vector Searches -> Re-ranker -> ACL Check -> LLM Generator -> User. Show decision points and loops. – ” />
Query Classifier -> Decomposer (for complex queries) -> Parallel Vector Searches -> Re-ranker -> ACL Check -> LLM Generator -> User. Show decision points and loops. – ” />Level 4: Autonomous RAG (The Future)
This is the bleeding edge. The system actively seeks to improve its own knowledge base.
* Key Additions:
* Automated Knowledge Curation: The system identifies gaps in its knowledge (“I was asked about ‘Project Z’ 10 times but have no documents”) and can automatically task humans or other agents to find or create that information.
* Self-Correcting Data: The system detects conflicting information across documents and flags it for review, ensuring the knowledge base becomes more accurate over time.
Pros and Cons of Production-Grade RAG
| Pros | Cons |
|---|---|
| High Accuracy & Relevance: Answers are grounded in your specific data, reducing hallucinations. | Complex Implementation: Requires significant data engineering and architecture expertise. |
| Real-Time Knowledge: Can be connected to live data streams for up-to-the-minute information. | Higher Initial Cost: More components (vector DB, re-ranker, etc.) than a simple LLM call. |
| Secure & Auditable: Allows for granular, user-level access control on data. | Maintenance Overhead: The data pipeline needs monitoring and maintenance like any other critical system. |
| Proprietary Moat: Creates a competitive advantage that can’t be replicated by others. | Requires a Strategic Vision: Must be treated as a core infrastructure project, not a quick feature add. |
The Retrospective: Why My First Enterprise RAG Agent Failed
In 2022, I was tasked with building an internal “expert” for a 10,000-person engineering organization. The goal was to answer technical questions about our complex microservices architecture. My team and I built a classic Level 1 RAG system on top of 50,000 pages of Confluence documentation.
It was a disaster.
- The Chunking Catastrophe: Our naive, 512-token fixed-size chunking split code blocks and tables right down the middle, making them incomprehensible. The context provided to the LLM was garbage.
- The Stale Data Plague: The documentation was constantly changing. Our weekly batch indexing meant the agent was frequently providing answers based on deprecated services, causing real confusion for junior developers.
- The “Permission Denied” Paradox: The agent had god-mode access to all docs, but the users didn’t. It would confidently synthesize answers from documents the user wasn’t allowed to see, creating a frustrating and untrustworthy experience.
We had to scrap the entire thing and start over, this time with a Level 2, data-centric approach. It was a humbling but invaluable lesson: The quality of your retrieval pipeline is 10x more important than the choice of your LLM.
Call to Action
Your RAG pilot is a valuable first step, but it’s not a foundation for an enterprise-grade product. Pushing a Level 1 system into production will lead to user frustration, wasted cloud spend, and a loss of credibility for your innovation team.
I help CTOs and VPs of Engineering assess their current RAG implementation against the Maturity Model and build a pragmatic, step-by-step roadmap to a production-ready system.
Book a 1-hour RAG Strategy Assessment with Paul Cannon
[IMAGE_PROMPT: A professional headshot of Paul Cannon, looking approachable but expert. The background is a clean, modern office. Text overlay: "Build Your Production RAG Roadmap."]
FAQ: Objection Handling
1. Is this secure enough for our enterprise data?
Absolutely, but only if designed for it from the start. A Level 3 architecture incorporates security at the retrieval step. Before context is passed to the LLM, the system checks the user’s permissions against the Access Control List (ACL) of each source document chunk. This ensures a user can never see data they aren’t authorized to, even if the LLM synthesizes an answer from it. This is a non-negotiable for any enterprise deployment.
2. This sounds expensive. What’s the real cost?
The cost of a naive RAG pilot is deceptively low. The cost of a failed production RAG system is astronomical (wasted engineering hours, cloud spend, and reputational damage). A proper, Level 3 architecture is more expensive upfront but has a much lower Total Cost of Ownership (TCO). By implementing intelligent caching, re-ranking (using a cheap model to protect the expensive LLM), and query optimization, we often reduce the cost-per-query by 60-70% compared to a brute-force approach.
3. Can’t we just fine-tune a model on our data instead?
Fine-tuning and RAG solve different problems. Fine-tuning teaches a model a new skill or style (e.g., to speak like a lawyer). It does not teach it new facts. Knowledge learned during fine-tuning becomes static and cannot be updated without re-training the entire model. RAG allows the model to access real-time, dynamic information. The best systems often use both: RAG to provide timely facts, and a fine-tuned model to provide those facts in the correct tone and format.
4. How do we avoid vendor lock-in with all these components?
This is a critical architectural consideration. My approach emphasizes using open-source components (like LlamaIndex/LangChain for orchestration, Weaviate/Qdrant for vector DBs) and cloud-agnostic principles wherever possible. The key is to build the architecture around standardized interfaces. This allows you to swap out an embedding model, a vector database, or even a foundational LLM with minimal disruption as the technology landscape evolves.
5. How do we handle the sheer scale and diversity of our data?
This is the core challenge that the Maturity Model is designed to solve. You don’t boil the ocean. We start by identifying the most valuable, highest-quality data source and building a robust Level 2 ingestion pipeline for it. We create content-aware chunking strategies for each specific data_type (PDF, Slack, Jira, Code). The system is built modularly, so adding new data sources is a repeatable, manageable process, not a monolithic rewrite.


![Llama 3 vs Mistral Benchmark: A Data-Driven Analysis [2025]](https://paulscannon.com/wp-content/uploads/2026/01/article_image_1768324461_943-768x419.png)