
CTO’s Guide to RAG: Architecture, Costs & Performance
Your LLM is lying to you. Not maliciously, but because it’s operating in a vacuum of pre-trained knowledge, disconnected from your company’s real-time, proprietary data. Retrieval-Augmented Generation (RAG) is the most pragmatic solution to ground your AI in your business reality, but most enterprise implementations I’ve seen fail due to a misunderstanding of its architectural complexity and operational costs. This guide provides the blueprint to get it right.
Executive Summary
Retrieval-Augmented Generation (RAG) is not a plug-and-play technology; it’s an architectural pattern that connects a Large Language Model (LLM) to an external, authoritative knowledge base. This allows the LLM to generate answers based on specific, verifiable corporate data instead of its generalized training set.
- The Business Case: RAG directly mitigates LLM “hallucinations,” enables the use of real-time data without costly model retraining, and provides source-linked answers, which is critical for compliance and user trust.
- The Core Architecture: A RAG system has two main workflows: an offline Indexer that processes and vectorizes your documents, and an online Retriever-Generator pipeline that finds relevant context and synthesizes an answer for each user query.
- The Primary Failure Point: The entire system’s value hinges on the Retriever. If it cannot find the correct context from your knowledge base, the LLM is flying blind, and the output will be useless. Success requires a sophisticated strategy for data parsing, chunking, and retrieval evaluation.
- The Economics: Costs are driven by three components: a one-time embedding cost during indexing (cheap), recurring vector database hosting costs (moderate), and per-query LLM token costs (can be significant). A poorly optimized system can easily lead to budget overruns with little to show for it.

The Business Case: Why RAG is a Strategic Imperative
Before we dive into the architecture, let’s be clear about the strategic value. As a CTO, you’re not just evaluating a new tool; you’re evaluating a new capability. I’ve seen RAG deliver transformative results when implemented correctly, primarily in three areas:
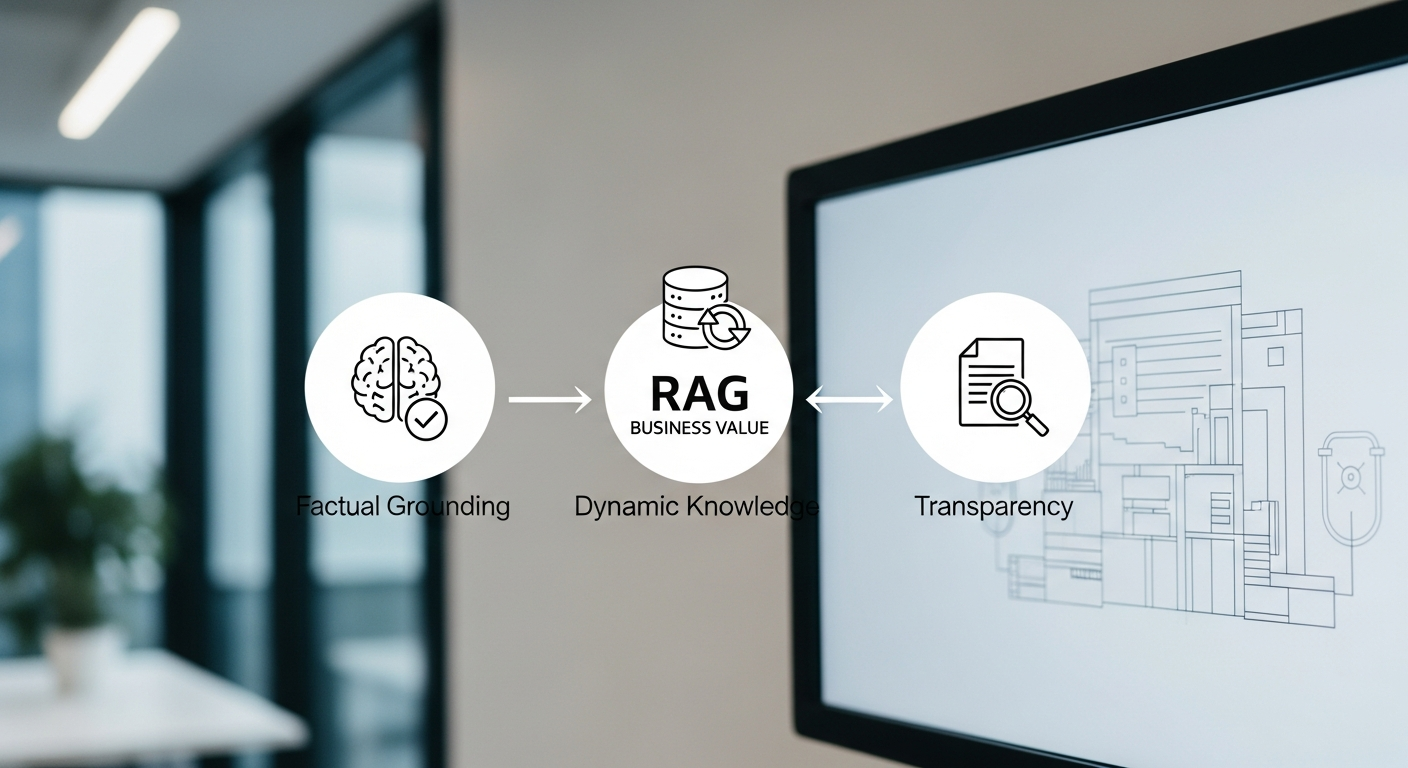
- Factual Grounding & Hallucination Reduction: Standard LLMs invent facts when they don’t know an answer. This is unacceptable for enterprise use cases like customer support bots or internal knowledge search. RAG forces the LLM to construct its answer only from the context documents we provide. If the information isn’t in the knowledge base, the model can be instructed to say, “I don’t know,” which is infinitely more valuable than a confident-sounding lie.
- Dynamic Knowledge Integration: Your business data changes daily—new product specs, updated compliance policies, real-time inventory levels. Fine-tuning an LLM on this data is slow, expensive, and impractical. RAG allows your knowledge base to be updated independently and in near real-time. Simply re-index the new or modified documents, and your AI is instantly up-to-date without ever touching the base model.
- Transparency and Auditability: When a RAG system provides an answer, it can also cite the specific sources it used. This is a game-changer. For a legal team researching case law or an engineer debugging a system failure, knowing the exact document and passage that informed the AI’s conclusion builds trust and creates an auditable trail.
The Architecture: A Two-Part System
A production-ready RAG system is not a single monolith. It’s a pipeline of discrete services that must be architected, scaled, and monitored independently. I break it down into the Offline Indexing Pipeline and the Online Query Pipeline. This approach is fundamental to understanding not just what Generative AI is, but how to apply it effectively in a business context.
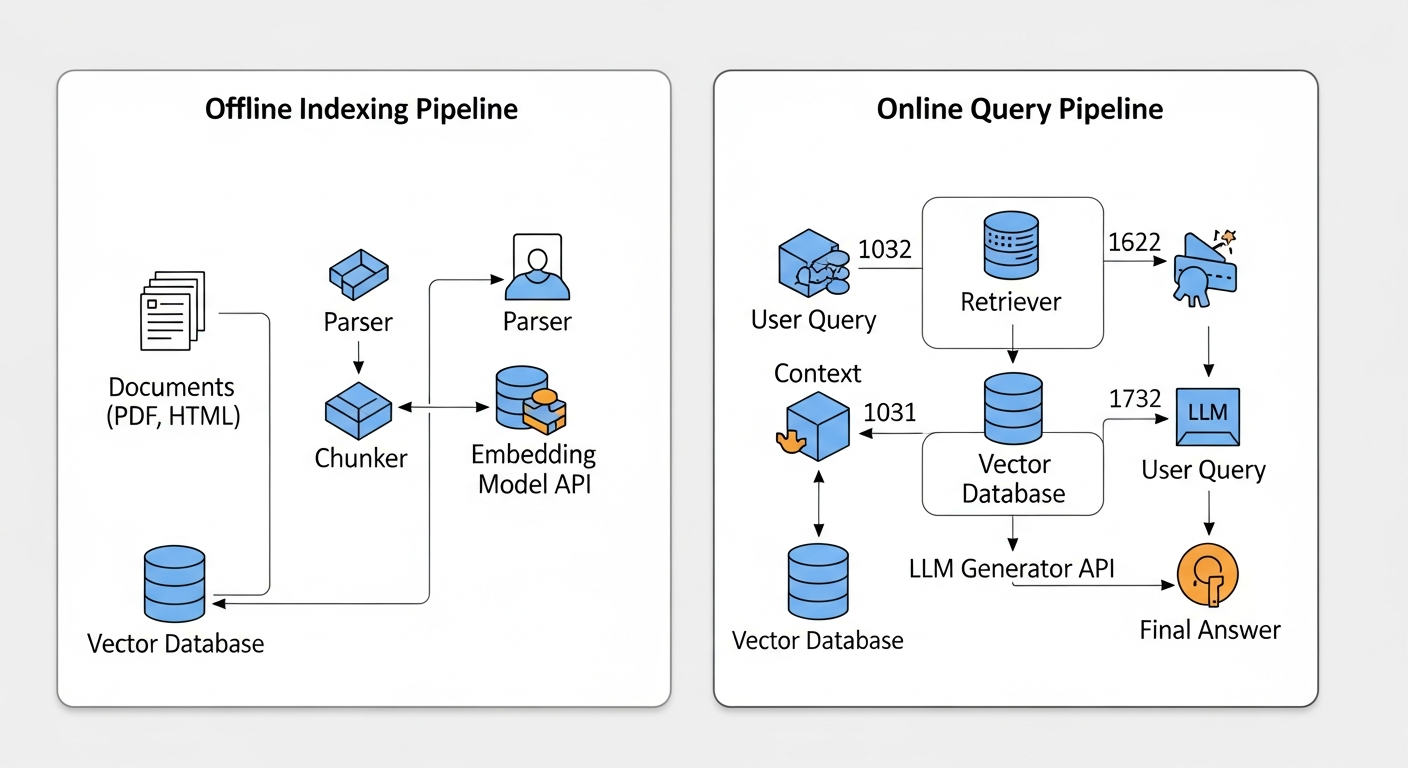
1. The Offline Indexing Pipeline
This is the foundational, back-end process that prepares your knowledge. It runs asynchronously, typically on a schedule or triggered by new document uploads.
- Load & Parse: Your raw data (PDFs, Confluence pages, Word docs, code repositories) is ingested. A parser extracts the clean text, stripping away irrelevant formatting.
- Chunk: This is a critical and often underestimated step. The clean text is divided into smaller, semantically coherent segments or “chunks.” A naive fixed-size chunking strategy (e.g., every 1000 characters) is a common cause of failure, as it can split a single idea across multiple chunks. More advanced strategies involve sentence-aware or recursive chunking.
- Embed: Each chunk is passed to an embedding model (like
text-embedding-3-small). This model converts the text into a high-dimensional vector (a list of numbers) that captures its semantic meaning. - Store: These vectors, along with their corresponding text and metadata, are loaded into a specialized Vector Database. There are many cloud database solutions available, but for RAG, you need one optimized for vector search like Pinecone, Weaviate, or a self-hosted solution using FAISS.
2. The Online Query Pipeline
This is the real-time, user-facing process that generates answers. Latency here is critical.
- Query Embedding: The user’s query is converted into a vector using the exact same embedding model from the indexing stage.
- Retrieve: The query vector is sent to the Vector Database. The database performs a similarity search (e.g., Cosine Similarity) to find the
top-kdocument chunks whose vectors are most similar to the query vector. This is the “retrieval” in RAG. - Augment & Generate: The retrieved chunks of text (the “context”) are combined with the original user query into a carefully crafted prompt. This augmented prompt is then sent to a generator LLM (like
gpt-4o). The prompt explicitly instructs the model: “Answer the user’s question based only on the following context.” This step is a practical application of the skills covered in our guide to mastering prompt engineering. - Respond: The LLM generates the answer, which is then passed back to the user, often with citations pointing to the source chunks.
Here is a simplified diagram of the logic flow:
Pros and Cons of Retrieval-Augmented Generation (RAG)
| Pros | Cons |
|---|---|
| Reduces Hallucinations: Grounds LLM answers in verifiable, factual data. | Complex Architecture: Requires careful engineering of a multi-step pipeline. |
| Real-Time Knowledge: Easily updated with new information without retraining the model. | Retrieval is a Single Point of Failure: If the retriever fails, the entire system fails. |
| Cost-Effective: Cheaper than fine-tuning models for knowledge injection. | Difficult to Evaluate: Requires nuanced metrics beyond simple accuracy. |
| Transparency & Trust: Can cite sources, providing an auditable trail for answers. | Chunking Strategy is Critical: Poor chunking leads to incomplete context and wrong answers. |
The RAG Maturity Model: From Prototype to Self-Correcting System
Most teams start with a simple script and a Jupyter notebook. This is Level 1. Reaching enterprise-grade reliability requires a deliberate journey through several stages of maturity.
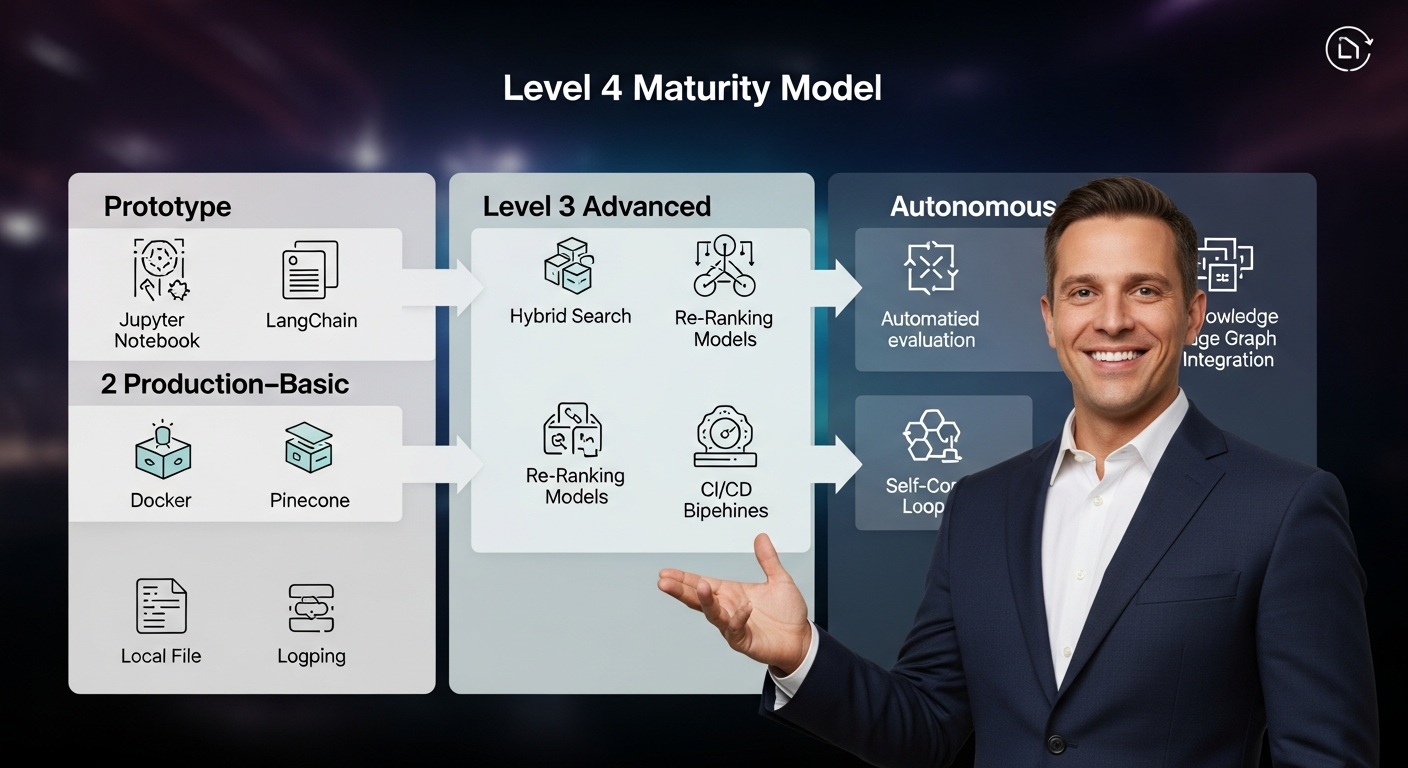
- Level 1: Prototype. A proof-of-concept, often in a notebook. Uses basic libraries like LangChain, a simple embedding model, and an in-memory vector store like FAISS. Goal: Demonstrate feasibility.
- Level 2: Production-Basic. The system is containerized (Docker), uses a managed vector database (Pinecone), and has basic logging. Chunking and prompting are static. Goal: Serve initial users and gather data.
- Level 3: Advanced. This is where real engineering begins. We introduce more sophisticated retrieval techniques like hybrid search (keyword + vector), a re-ranking model to improve the relevance of the
top-kresults, and a CI/CD pipeline for automated testing and deployment of the RAG components. Goal: Improve retrieval accuracy and operational robustness. - Level 4: Autonomous. The system is self-aware. It includes an automated evaluation pipeline (using metrics like Faithfulness and Context Relevance) that constantly measures performance. When a failure pattern is detected (e.g., poor retrieval for a certain type of query), it can trigger alerts or even self-correcting actions, like re-indexing a document with a different chunking strategy. Goal: Achieve high reliability with minimal human intervention.
The Retrospective: Why My First RAG Agent Failed
My first major RAG project for a financial services client was a near-disaster. We built a Level 2 system to answer questions about complex internal compliance policies. The PoC was great, but in production, the answers were often vague or incorrect. The post-mortem revealed two critical failures:
- Naive Chunking: We used a fixed-size chunker. A single compliance rule, which spanned three paragraphs, was split across two different chunks. When a user asked about that rule, the retriever would often only pull one of the two chunks, giving the LLM incomplete context and leading to a wrong answer.
- The “Lost in the Middle” Problem: We retrieved the
top-10chunks to be safe. Academic research, like the paper “Lost in the Middle: How Language Models Use Long Contexts”, has shown that in a long context window, LLMs pay more attention to the beginning and end of the context, often ignoring information “lost in the middle.” Our most relevant chunk was often ranked 4th or 5th, and the LLM simply overlooked it.
We fixed this by moving to a Level 3 architecture: implementing a sentence-aware chunking strategy and adding a lightweight cross-encoder model to re-rank the top 10 results, ensuring the most relevant chunk was always placed at the top of the prompt.
Code Implementation: A Glimpse into the Logic
This is not production code, but it illustrates the core orchestration logic using Python and a LangChain-like syntax. This is a key step in learning how to use AI in business for competitive advantage.
This snippet shows how an orchestration framework connects the retriever, the prompt, and the LLM into a single, invocable chain.
The Economics: Deconstructing the Cost of a Query
The TCO of a RAG system goes beyond API calls, but understanding the direct costs is the first step. Let’s model the cost for a system with 1 million documents and 10,000 user queries per month.
Assumptions:
* Average document size: 2,000 tokens
* Embedding Model: text-embedding-3-small ($0.02 / 1M tokens)
* Generator Model: gpt-4o ($5.00 / 1M input, $15.00 / 1M output)
* Vector DB: Pinecone Standard Pod (~$70/month)
* Context per query: 5 chunks of 512 tokens each = 2,560 tokens
* Average answer size: 200 tokens

| Cost Component | Calculation | Estimated Cost | Frequency |
|---|---|---|---|
| 1. Indexing (One-Time) | 1M docs * 2k tokens/doc = 2B tokens. (2B / 1M) * $0.02 | $40.00 | One-Time |
| 2. Vector DB Hosting | 1 Pinecone s1 pod (estimate) |
~$70.00 | Monthly |
| 3. Querying (Recurring) | Input: (10k queries * 2.56k tokens) * ($5/1M) = $128 Output: (10k queries * 0.2k tokens) * ($15/1M) = $30 |
~$158.00 | Monthly |
| Total Monthly OpEx | ~$228.00 |
The one-time indexing cost is negligible. The recurring cost is driven by the generator LLM and the vector database hosting. This model shows that for a moderate workload, the costs are manageable. However, if you have 1 million queries per month, that query cost balloons to $15,800/month. This is why optimizing the retrieval step to send less, more relevant context is not just a performance issue—it’s a financial one.
Your Next Move
You don’t need another PoC that works “sometimes.” You need a production-ready, scalable, and cost-effective architecture for leveraging your proprietary data with AI. The difference between a successful RAG implementation and a failed science project is in the operational details: the chunking strategy, the evaluation pipeline, and the retrieval-ranking mechanisms.
I help executive teams bridge the gap between C-suite strategy and engineering reality. If you’re ready to move beyond the hype and build a RAG system that delivers real business value, let’s talk.
FAQ: Objection Handling for Leadership
1. Is this secure enough for our enterprise data?
Security is paramount. A well-architected RAG system never sends your raw documents to the LLM provider. Only the small, retrieved chunks of text are sent in the prompt. Furthermore, the architecture must incorporate your existing access control lists (ACLs). When indexing, we tag each vector with its source permissions. At query time, the retrieval step filters results based on the user’s credentials, ensuring they can only see information they are already authorized to access. Data can be processed in your own VPC, and API calls are encrypted in transit.
2. How does this scale to millions of documents?
Scalability is an engineering challenge, not a fundamental barrier. The indexing process is a batch operation that can be parallelized and distributed using cloud services like AWS Batch or Google Cloud Run. The bottleneck is typically the vector database. Managed services like Pinecone are designed for this scale, handling billions of vectors. For self-hosted solutions, this requires careful sharding and replication of the index across multiple nodes.
3. What’s the real Total Cost of Ownership (TCO)?
The API and hosting costs are just the beginning. The real TCO includes:
* Development & Maintenance: The engineering effort to build and maintain the Level 3/4 architecture.
* Evaluation & Monitoring: The human and computational cost of running evaluation pipelines to ensure the system remains accurate.
* Data Pipeline Costs: The cost of running the ETL/ELT jobs for the indexing pipeline.
A good rule of thumb is that for every dollar you spend on APIs, you should budget at least another dollar for the engineering and operational overhead to ensure it’s being spent effectively.
4. Can’t we just fine-tune a model instead?
RAG and fine-tuning solve different problems.
* Fine-tuning is best for teaching a model a new skill or style (e.g., how to speak like your brand’s legal counsel). It is not effective for memorizing factual knowledge and is slow to update.
* RAG is best for injecting factual, up-to-date knowledge into the model at runtime.
Often, the best systems use both: a model fine-tuned for a specific task (like summarizing legal documents) that then uses RAG to access the specific documents it needs to summarize.
5. How do we even know if it’s working correctly?
This is the most important question. You cannot rely on anecdotal evidence. A robust RAG system requires a dedicated evaluation pipeline that continuously measures performance on a “golden dataset” of questions and answers. As detailed in recent research on RAG evaluation, we use a suite of metrics:
* Context Precision & Recall: Did we retrieve the right chunks?
* Faithfulness: Does the generated answer stick strictly to the provided context?
* Answer Relevance: Does the answer actually address the user’s question?
These metrics, tracked over time, provide the objective data needed to diagnose problems and prove the system’s ROI.

