
Llama 3 vs Mistral Benchmark: A Data-Driven Analysis [2025]
Choosing your foundational open-source model is no longer a simple benchmark race; it’s a critical architectural decision with multi-year cost and capability implications. The current debate pits Meta’s raw-power Llama 3 against Mistral’s hyper-efficient Mixture-of-Experts (MoE) models. Making the wrong choice means either overspending millions on idle compute or deploying a system that fails to meet performance SLAs.
This guide is not another roundup of marketing benchmarks. It’s an operational architect’s breakdown of the trade-offs, based on real-world deployment data, developer sentiment, and a clear-eyed view of the total cost of ownership. We will dissect the architectures, quantify the business impact, and provide a framework for you to make the right strategic bet.
Executive Summary: The Two Paths to AI Value
For leaders who need the answer first, here it is:
- Choose Llama 3 70B for Maximum Capability: When your primary objective is achieving state-of-the-art performance that rivals closed-source giants like GPT-4, and you have the budget for premium compute (think multi-H100 or A100 nodes), Llama 3 70B is the undisputed heavyweight. It’s a generalist powerhouse that excels in complex reasoning and coding tasks out of the box. The strategic bet here is on premium quality justifying a higher operational expenditure.
- Choose Mixtral (8x7B or 8x22B) for Operational Efficiency: When your goals are scalability, cost control, and architectural flexibility, Mistral’s MoE models are the clear choice. They deliver the performance of a much larger dense model but at a fraction of the inference cost and latency. The strategic bet is on long-term TCO reduction and the freedom afforded by the Apache 2.0 license, even if it requires more initial engineering effort to optimize.

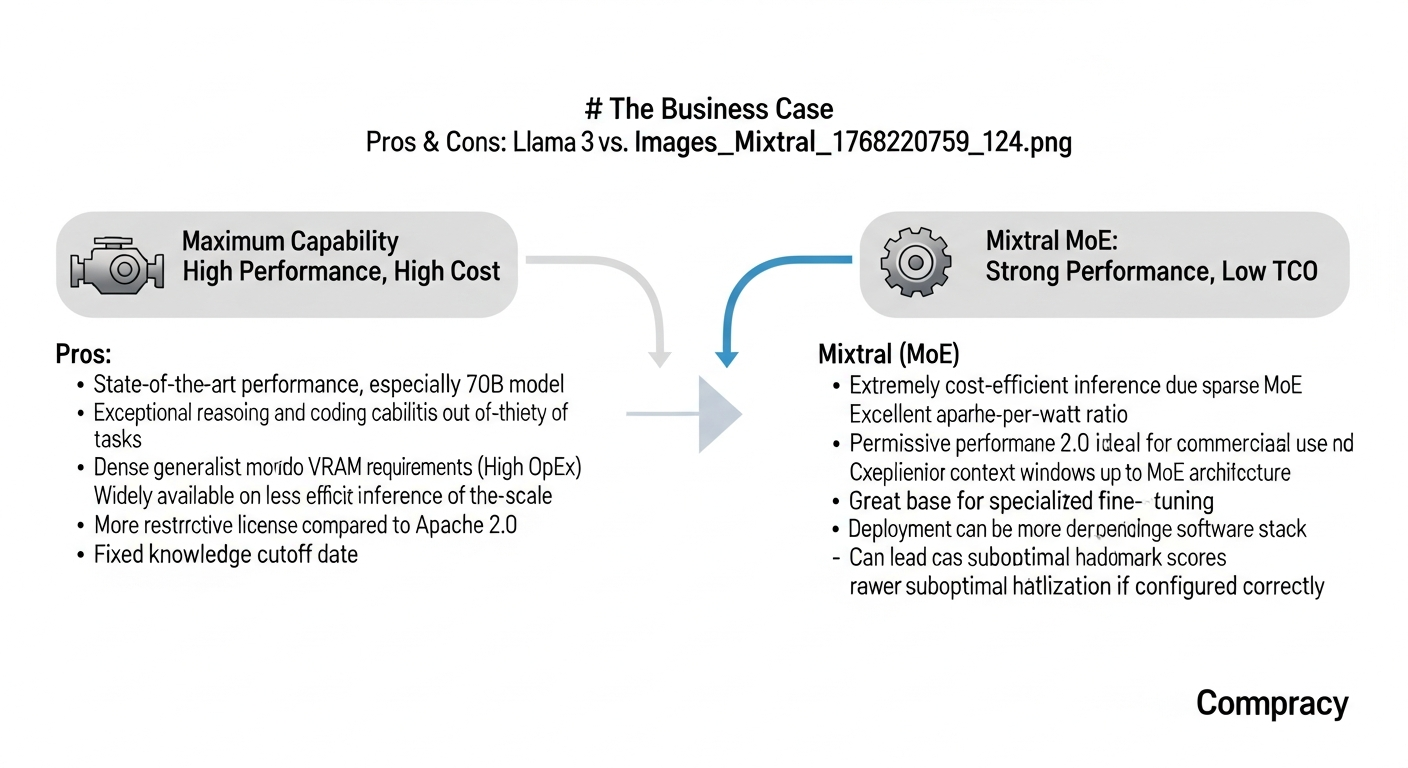
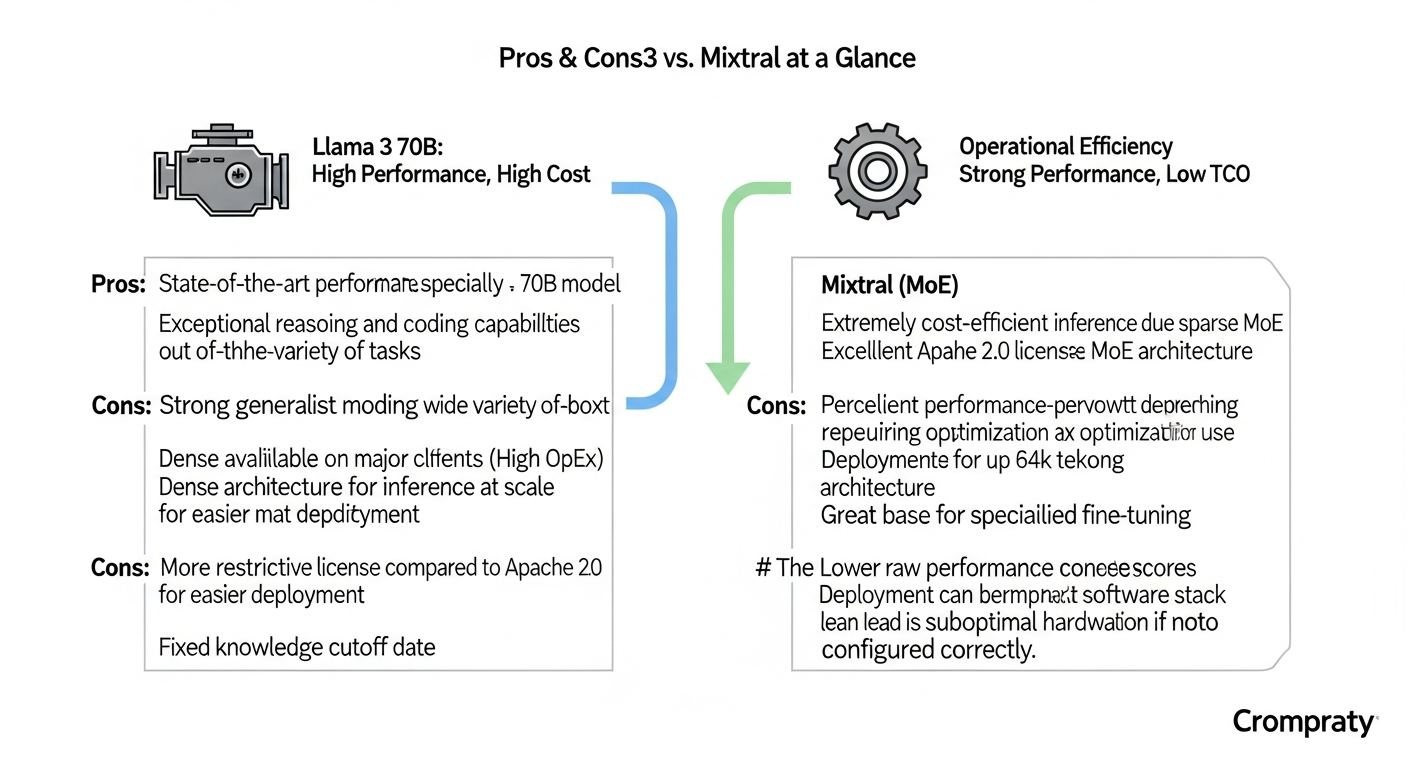
Pros & Cons: Llama 3 vs. Mixtral at a Glance
For a quick decision framework, here are the core advantages and disadvantages of each model family.
Llama 3
* Pros:
* State-of-the-art performance, especially the 70B model.
* Exceptional reasoning and coding capabilities out-of-the-box.
* Strong generalist model for a wide variety of tasks.
* Widely available on major cloud platforms for easier deployment.
* Cons:
* Very high computational and VRAM requirements (High OpEx).
* Dense architecture is less efficient for inference at scale.
* More restrictive license compared to Apache 2.0.
* Fixed knowledge cutoff date.
Mixtral (MoE)
* Pros:
* Extremely cost-efficient inference due to sparse MoE architecture.
* Excellent performance-per-watt ratio.
* Permissive Apache 2.0 license is ideal for commercial use and modification.
* Large context windows (up to 64k tokens).
* Great base for specialized fine-tuning.
* Cons:
* Can have performance inconsistencies depending on hardware and software stack.
* Deployment can be more complex, requiring optimization for MoE architecture.
* Lower raw benchmark scores compared to Llama 3 70B.
* Can lead to suboptimal hardware utilization if not configured correctly.
The Business Case: Power vs. Pounds Sterling
The decision between Llama 3 and Mixtral is a classic business trade-off between CapEx/OpEx and performance. I’ve seen teams get mesmerized by benchmark scores, only to face a six-figure monthly cloud bill that kills the project’s ROI.
Llama 3’s Value Proposition: Raw intellectual horsepower. On benchmarks like GSM8K (math) and HumanEval (coding), the 70B model is a monster. For a hedge fund building a quantitative analysis agent or a software company developing a sophisticated code generation tool, the incremental accuracy of Llama 3 can directly translate into millions in alpha or developer productivity. The business case is simple: you pay a premium for a premium, measurable result. The risk is the high, fixed cost of the underlying infrastructure.
Mixtral’s Value Proposition: Performance-per-watt. The MoE architecture is the game-changer here. While the Mixtral 8x22B model has 176 billion total parameters, it only activates a fraction (~44B) for any given token. This is the equivalent of having a large team of specialists on call but only paying for the two or three you consult for a specific task. For businesses building customer-facing chatbots, content summarization tools, or internal knowledge retrieval systems at scale, this efficiency translates directly to lower latency, a better user experience, and a dramatically lower cost-per-inference. The permissive Apache 2.0 license further de-risks the investment, eliminating licensing concerns for commercial modification and distribution.
The Architecture Showdown: Dense vs. Sparse
To make an informed decision, you must understand the fundamental architectural difference. It’s not just about parameter count; it’s about how those parameters are utilized.
- Dense Architecture (Llama 3): Think of this as a single, massive brain. For every single token you process, the entire 70 billion parameter model is activated. This ensures maximum contextual awareness and reasoning power for that token, but it’s computationally brutal. It’s the reason for the high VRAM requirements and inference latency.
- Sparse Mixture-of-Experts (Mixtral): Think of this as a board of specialized experts. The model consists of multiple smaller “expert” networks and a “router” that decides which one or two experts are best suited to process the incoming token. The other experts remain dormant. This is why Mixtral 8x7B can perform like a 47B parameter model while only using the compute equivalent of a ~13B model at inference time.
The Strategic Decision Framework
I advise my clients to map their primary use case on a simple 2×2 matrix. This immediately clarifies which architectural path aligns with their strategic goals.
Benchmark Analysis: The Numbers Don’t Lie, But They Don’t Tell the Whole Story
The benchmarks from sources like Meta’s own announcement and independent analysis confirm the architectural trade-offs. Llama 3 70B is the clear leader in raw scores, but Mixtral’s performance, especially in coding, is remarkably strong given its efficiency.
| Specification | Llama 3 8B | Llama 3 70B | Mixtral 8x7B-Instruct | Mixtral 8x22B |
|---|---|---|---|---|
| Architecture | Dense | Dense | Sparse MoE | Sparse MoE |
| Active Parameters | 8B | 70B | ~13B | ~44B |
| Context Length | 8K | 8K | 32K | 64K |
| License | Llama 3 License | Llama 3 License | Apache 2.0 | Apache 2.0 |
| MMLU (Knowledge) | 68.4 | 82.0 | 70.6 | ~77.8 |
| GSM8K (Math) | 79.6 | 94.1 | 61.1 | ~84.1 |
| HumanEval (Code) | 62.2 | 81.7 | 73.2 | ~77.8 |
My Operational Take:
- MMLU (General Knowledge): Llama 3 70B’s score of 82.0 is near GPT-4 level. This is critical for applications requiring nuanced understanding of complex topics. Mixtral’s scores are strong, but Llama 3 has the edge for pure “smarts.”
- GSM8K (Math/Reasoning): The staggering 94.1 score for Llama 3 70B demonstrates its superior multi-step reasoning capability. For financial modeling, scientific research, or complex logic puzzles, this is a significant differentiator.
- HumanEval (Coding): This is where it gets interesting. While Llama 3 70B wins, Mixtral 8x7B’s 73.2 is incredibly impressive for its size, and the newer 8x22B is closing the gap. This suggests Mixtral is an excellent, cost-effective base for many of the ways AI is used in business today, especially developer tools. The larger context windows (64k for Mixtral 8x22B vs 8k for Llama 3) are also a massive practical advantage for code analysis.
The Implementation Reality: Where Strategy Meets the Silicon
This is where my work as an operational architect begins. A model on a leaderboard is useless until it’s running reliably in a production environment.
Llama 3: The VRAM Beast
Running the Llama 3 70B model is not trivial. In its native bfloat16 precision, it requires over 140GB of VRAM. Even with 4-bit quantization, you’re looking at ~40GB of VRAM, which means you need at least one A100 80GB or two H100 GPUs just for the model weights. This is a significant consideration for your cloud operations budget.

Mixtral: The Optimization Puzzle
Mixtral’s efficiency promise comes with an engineering asterisk. As reported in the vLLM and llama.cpp communities, getting optimal throughput requires careful tuning. The MoE architecture can lead to load-balancing challenges where some experts on one GPU are overloaded while others sit idle.
I’ve seen teams struggle with this, observing lower-than-expected throughput because their inference server wasn’t correctly batching requests or managing the expert parallelism. This isn’t a flaw in the model, but a reflection of its complexity. It requires a deeper level of engineering expertise to deploy effectively compared to a dense model.
Code Implementation: A Glimpse into Practice
Here’s a simplified Python snippet using the transformers library to illustrate the conceptual loading process. In a real-world scenario, you’d use an optimized inference server like vLLM, TensorRT-LLM, or TGI.
The Retrospective: My Recommendation as Your Architect
There is no single “best” model. The best model is the one that fits your unique balance of performance requirements, user scale, budget, and in-house engineering capability.
- If you are a well-funded R&D team or building a premium, low-volume B2B product where accuracy is paramount, choose Llama 3 70B. Absorb the higher cost as a necessary investment for best-in-class capability.
- If you are an enterprise building a scaled internal or external application (e.g., >1M requests/day), and you have a competent MLOps team, the long-term TCO benefits of Mixtral 8x22B are impossible to ignore. The initial engineering investment to optimize deployment will pay for itself many times over.
- If you are a startup or a team prototyping new features, the Mixtral 8x7B model offers an incredible blend of performance and affordability. Its Apache 2.0 license and large context window make it a flexible and powerful starting point.
The open-source landscape is no longer about finding one model to rule them all. It’s about building a portfolio of capabilities. Your most critical agent might run on Llama 3 70B, while your customer support chatbot runs on a fine-tuned Mixtral model for cost-effective scale. The true art is in the architecture that orchestrates them.
Frequently Asked Questions (Objection Handling)
1. Is Mixtral’s reported performance inconsistency a deal-breaker for production?
No, but it requires mitigation. The inconsistencies often stem from suboptimal deployment configurations, not the model itself. Using mature, MoE-aware inference servers like vLLM (with recent updates) or NVIDIA’s TensorRT-LLM, and performing rigorous load testing on your target hardware, is non-negotiable. It’s an engineering problem, not a fundamental model flaw.
2. Is the custom Llama 3 license “open” enough for my enterprise?
For most use cases, yes. It allows for commercial use, modification, and distribution. The primary restriction is that you cannot use it to train other foundational models, which is not a concern for most enterprises. However, your legal team must review it. The Apache 2.0 license of Mistral’s models is undeniably more permissive and is the gold standard, which can be a deciding factor for companies with a low tolerance for legal ambiguity.
3. How can I realistically manage the high VRAM and operational costs of Llama 3 70B?
First, aggressively quantize the model to 4-bit (using formats like AWQ or GPTQ) to reduce the memory footprint by ~4x with minimal performance loss. Second, implement intelligent request batching to maximize GPU utilization. Third, leverage cloud spot instances and other FinOps strategies for cloud cost management. Finally, for real-time APIs, use auto-scaling groups with scale-to-zero capabilities to avoid paying for idle GPUs.
4. Is the MoE architecture in Mixtral secure for sensitive data in a multi-tenant environment?
The security model is no different than for a dense model. The “router” and “experts” are all part of the same process. Data isolation is the responsibility of the serving infrastructure, not the model architecture itself. If you are serving multiple tenants from a single model deployment, you need a robust application layer and strong cloud security practices to ensure data segregation, regardless of whether the model is dense or sparse.
5. Which model is a better base for fine-tuning on proprietary data?
Both are excellent fine-tuning bases. However, Mixtral’s MoE architecture offers an interesting advantage: you could potentially fine-tune only a subset of the experts on specific tasks, creating a highly specialized yet efficient model. Llama 3’s dense architecture is more straightforward to fine-tune using standard techniques like LoRA. For cost-sensitive fine-tuning projects, starting with the smaller Llama 3 8B or Mixtral 8x7B is often more practical and can yield surprisingly powerful results. Learning to master prompt engineering is a crucial first step before committing to a full fine-tuning project.


