Production RAG Pipelines: Architecture to ROI [Guide]
Executive Summary
Your Large Language Model is a brilliant, but amnesiac, intern. It can reason, summarize, and write, but it has no memory of your company’s proprietary data. Retrieval-Augmented Generation (RAG) is the architectural pattern that gives your LLM a perfect, searchable memory of your internal knowledge base. It’s the difference between a generic chatbot and an enterprise-grade expert system. However, the path from a simple proof-of-concept (PoC) to a production-ready, reliable RAG system is fraught with architectural pitfalls in data processing, retrieval accuracy, and cost management. This article is the blueprint for CTOs and VPs of Engineering to navigate that complexity, outlining the architecture, the code, the advanced techniques, and the ROI of building RAG the right way.
Key Takeaways
- RAG Connects LLMs to Your Data: It’s the core technology for making Generative AI contextually aware of your private enterprise information.
- Architecture is Key: Production RAG requires a decoupled architecture with separate offline (Indexing) and online (Inference) pipelines.
- Pain Points are Predictable: Common challenges include poor data chunking, “missed retrievals,” and the LLM ignoring the provided context.
- Advanced Techniques are Necessary: To achieve high reliability, you must implement techniques like Hybrid Search, Re-Ranking, and Query Transformation.
- Measure Everything: Use frameworks like RAGAs to evaluate retrieval and generation quality to avoid silent failures in production.
The Business Case: Why RAG is Non-Negotiable for Enterprise AI
Enterprises are not in the business of building general-purpose chatbots. They are in the business of leveraging their unique data to create a competitive advantage. RAG is the primary mechanism for connecting the reasoning power of LLMs—a core component of what Generative AI is—to the proprietary data that defines your business. Gartner validates this, predicting that by 2028, 80% of Generative AI business applications will be developed on existing data management platforms—a clear signal of RAG’s central role.
The value isn’t theoretical; it’s measured in three core KPIs:
- Reduction in Hallucinations: By providing factual, grounded context with every query, RAG drastically reduces the model’s tendency to invent answers.
- Increase in Answer Relevance: The LLM’s responses are tailored to your specific domain, using your terminology, processes, and data.
- Citation & Verifiability: RAG provides a “proof of work” for every answer, linking back to the source documents. This builds trust and is non-negotiable for any regulated industry.
For a Fortune 500 client in the financial services sector, we implemented a RAG system for their internal compliance team. The system ingested thousands of pages of regulatory documents. The result was a 75% reduction in the time compliance officers spent searching for information and a measurable increase in the consistency of their advisory opinions. The business case is clear: RAG transforms LLMs from interesting novelties into mission-critical business tools, helping you gain a competitive advantage using Big Data and Machine Learning.
Pros and Cons of Retrieval-Augmented Generation
| Pros | Cons |
|---|---|
| Trust & Verifiability: Provides citations to source documents, allowing users to verify answers. | Implementation Complexity: Requires new skills in vector databases, embedding models, and chunking strategies. |
| Domain Specificity: Answers questions using company-specific knowledge (wikis, docs, support logs). | Retrieval Challenges: Can suffer from “missed retrievals” (correct info exists but isn’t found) or “noisy retrievals” (too much irrelevant info is found). |
| Reduced Hallucinations: Grounds the LLM in factual data, significantly lowering the chance of fabricated answers. | Generation Errors: The LLM can still ignore the provided context or fail to synthesize information correctly. |
| Timeliness: Knowledge can be updated in near real-time by simply adding new documents to the index, unlike fine-tuning. | Evaluation Difficulty: Measuring the quality of both retrieval and generation requires a sophisticated evaluation framework (e.g., RAGAs). |
The Core Challenge: Bridging the PoC-to-Production Gap
The internet is filled with five-line Python tutorials that create a “RAG” system. These are toys. They create the illusion of simplicity, but they fail under the weight of real-world complexity. My first scaled RAG agent was a disaster. It was built for a logistics company to query shipping manifests. It was slow, it frequently missed manifests that were clearly in the database, and it sometimes ignored the retrieved context entirely, defaulting to its generic knowledge about “shipping.”
The failure was one of architecture, not concept. We had underestimated the complexity of moving from a single-document PoC to a system that could handle thousands of heterogeneous files, real-time updates, and ambiguous user queries.
To guide this journey, I use the RAG Maturity Model. It’s a framework that helps organizations understand their current capabilities and map a deliberate path toward a robust, scalable system.
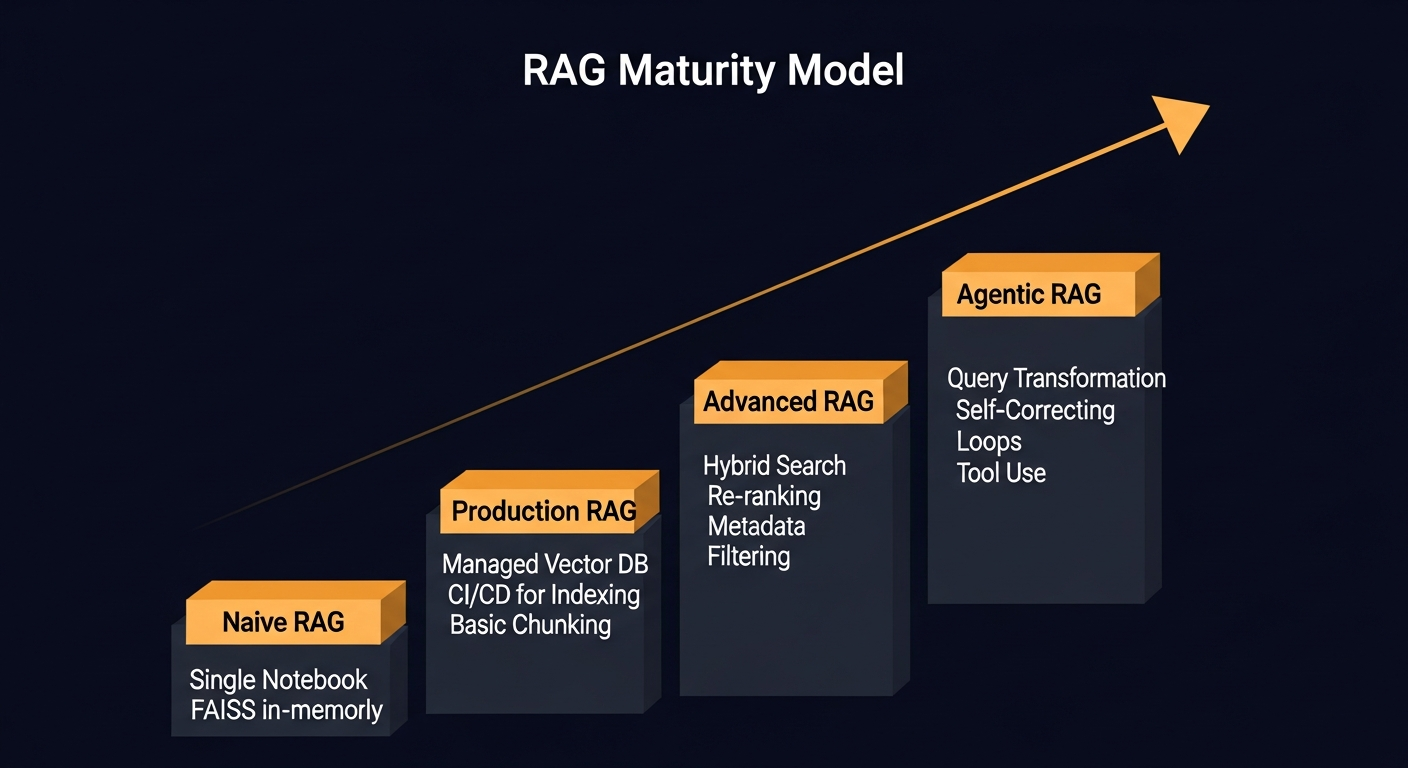
Most organizations get stuck between Stage 1 and Stage 2. This guide provides the architectural blueprint to get to Stage 3 and beyond.
The Architecture: A Three-Stage Blueprint
A production-grade RAG system is not one monolithic application; it’s a decoupled architecture with two distinct pipelines: an offline Indexing Pipeline and a real-time Inference Pipeline.
Stage 1: The Indexing Pipeline (Offline)
This is where the knowledge is prepared. Getting this right is 80% of the battle.
- Data Loading & Chunking: You can’t just dump a 300-page PDF into a vector database. You must break it down into meaningful, context-rich chunks. This is the “Chunking Dilemma.”
- Fixed-Size: Simple, but often cuts sentences in half, destroying meaning.
- Recursive Character: Smarter, tries to split on paragraphs and sentences. A good default.
- Semantic Chunking: The most advanced method. It groups text based on semantic similarity, ensuring that a single chunk represents a coherent idea. This is computationally expensive but yields the best retrieval results.
- Embedding: Each chunk is converted into a vector (a list of numbers) by an embedding model. Your choice here is critical.
- OpenAI
text-embedding-3-small/large: A powerful, managed, and cost-effective starting point. - Open-Source (e.g.,
bge-large-en): Offers more control and can be run in your own VPC for maximum security, but requires management of the model infrastructure. The performance can be superior for specific domains if fine-tuned.
- OpenAI
Stage 2: The Retrieval Pipeline (Real-time)
When a user asks a question, this pipeline finds the right knowledge.
- Vector Database: This is a specialized database designed for extremely fast similarity searches on vectors. Instead of
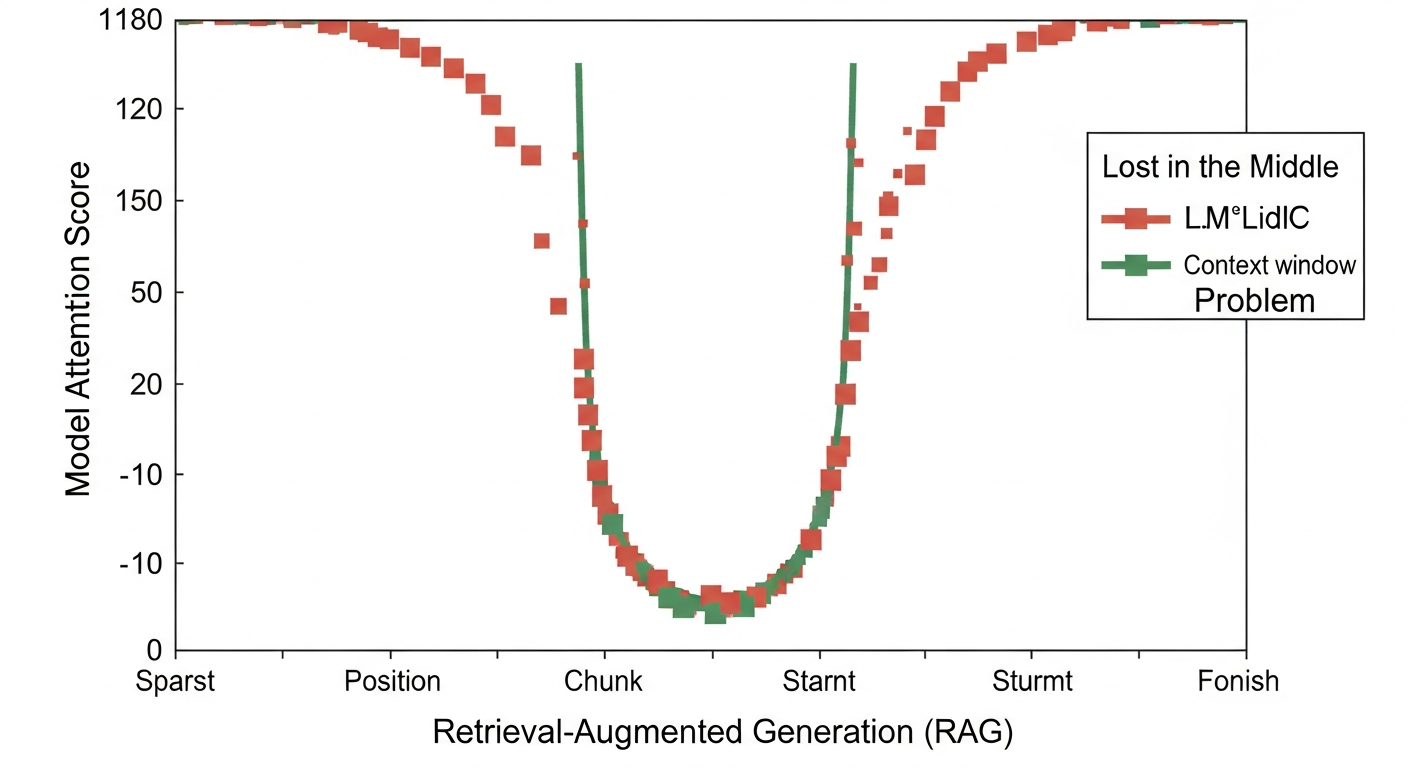
WHERE name = 'Paul', you’re askingSELECT document WHERE vector is most similar to <query_vector>. When exploring cloud database solutions, vector databases represent a new, critical category for AI applications. - The “Lost in the Middle” Problem: A common failure mode is retrieving the correct documents but having the LLM ignore them. Research shows that models pay more attention to information at the beginning and end of the prompt context. If you stuff 10 documents into the middle of your prompt, the LLM is likely to overlook the crucial one. This is why advanced techniques like re-ranking are essential.
Stage 3: The Generation Pipeline (Real-time)
This is where the retrieved knowledge and the user’s query are synthesized into a final answer.
- Prompt Engineering: The augmented prompt is not just a simple concatenation. It’s a carefully crafted instruction to the LLM. To dive deeper, see this guide to master prompt engineering.
“`
You are an expert AI assistant for [COMPANY]. Answer the user’s question based only on the following context documents.
If the answer is not found in the context, say “I could not find an answer in the provided documents.”
Cite the source document for each part of your answer using the [citation: document_name] format.CONTEXT:
[Document: compliance_policy_v3.pdf]
[Document: security_protocols.docx]
USER QUESTION:
ANSWER:
“`
* LLM Choice: The final step is the call to the generator model (e.g., GPT-4, Llama 3, Claude 3). The choice involves a trade-off between reasoning capability, speed, and cost. For complex queries requiring synthesis across multiple documents, a high-capability model like GPT-4 or Claude 3 Opus is often necessary. For simpler Q&A, a faster, cheaper model may suffice.
The Code: An Implementation Snapshot
Talk is cheap. Here is a pragmatic, high-level implementation using Python and LlamaIndex, which excels at the data indexing and retrieval aspects of RAG.

Leveling Up: Advanced RAG Techniques for Production
A basic RAG pipeline will get you to 70% accuracy. The final 30%—the part that makes the system truly reliable—comes from more advanced architectural patterns.
- Hybrid Search: Vector search is great for semantic meaning, but it can fail on specific keywords, SKUs, or acronyms. Hybrid search combines traditional keyword search (like BM25) with vector search, getting the best of both worlds. A query for “specs for model XG-500” will use keyword search to find “XG-500” and vector search to understand the meaning of “specs.”
 BM25 (Keyword) Search -> Ranked List A. Path 2 (bottom): User Query -> Embedding Model -> Vector Search -> Ranked List B. Both lists feed into a ‘Fusion’ box, which outputs a final, combined ‘Hybrid Search Result’. – “Retrieval-Augmented Generation (RAG)”” />
BM25 (Keyword) Search -> Ranked List A. Path 2 (bottom): User Query -> Embedding Model -> Vector Search -> Ranked List B. Both lists feed into a ‘Fusion’ box, which outputs a final, combined ‘Hybrid Search Result’. – “Retrieval-Augmented Generation (RAG)”” />- Re-Ranking: The initial retrieval from the vector database is fast but sometimes imprecise. A re-ranker adds a second step: a more powerful (but slower) model, typically a cross-encoder, re-evaluates the top 20-50 documents from the initial retrieval and re-orders them for relevance before sending the top 3-5 to the LLM. This dramatically improves the signal-to-noise ratio of the context.
- Query Transformation: Users ask messy, multi-part questions. Instead of passing a complex query like “How do our security protocols compare to our main competitor’s, and what are the cost implications?” directly to the retrieval system, a query transformation layer breaks it down into distinct sub-queries that can be run independently.
The Retrospective: Measuring Success and Avoiding Pitfalls
You cannot improve what you cannot measure. “Eyeballing” the output of a RAG system is a recipe for silent failure. A rigorous evaluation framework is mandatory for any production system.
Frameworks like RAGAs provide a suite of metrics to measure the distinct parts of your pipeline:
- Retrieval Quality:
context_precision: Are the retrieved documents relevant?context_recall: Did you retrieve all the relevant documents?
- Generation Quality:
faithfulness: Does the answer stick to the provided context? (Measures hallucinations)answer_relevancy: Is the answer actually relevant to the user’s question?
My biggest mistake on an early project was skipping the creation of a “golden dataset”—a curated set of question-answer-context triplets. Without it, we couldn’t run regression tests. When a data scientist “improved” our chunking strategy, it silently broke retrieval for a critical category of questions, a failure we only discovered through user complaints weeks later. A golden dataset and an automated evaluation pipeline would have caught this in staging.
Conclusion & The Path Forward
Retrieval-Augmented Generation is more than a technique; it’s a fundamental shift in how we build intelligent applications. It grounds the abstract reasoning power of LLMs in the concrete reality of your enterprise data.
Moving from a Jupyter Notebook PoC to a production-ready system is a significant engineering and architectural challenge. It requires a deliberate approach to data ingestion, chunking, retrieval strategy, and—most importantly—evaluation. By adopting a maturity model and implementing a robust, multi-stage architecture, you can build a RAG system that is not only powerful but also reliable, verifiable, and a true driver of business value.
The ‘product’ here isn’t the AI; it’s the trusted, contextualized answer that the AI provides. Building that requires an operational architect’s mindset.
FAQ: Answering the Hard Questions
1. Is this secure enough for our sensitive enterprise data?
Absolutely, provided it’s architected correctly. The architecture should utilize a VPC to isolate services. Data in the vector database should be encrypted at rest and in transit. By using open-source embedding models hosted within your own environment, no proprietary data ever needs to leave your cloud account. IAM roles, not static keys, should be used to grant services the minimum necessary permissions.
2. How do we manage the spiraling costs of embedding and LLM calls?
Cost management is an architectural concern. Key strategies include:
* Intelligent Caching: Cache responses for identical queries. Cache embeddings for documents that haven’t changed.
* Model Tiering: Use a cheaper, faster model (e.g., Claude 3 Haiku) to triage queries and only escalate to a more expensive model (e.g., GPT-4) when complexity is detected.
* Batching: Process documents for the indexing pipeline in batches to reduce the number of API calls.
3. What is the team skill set required to build and maintain this?
A cross-functional team is ideal. You need:
* ML Engineers: To manage the model infrastructure, embedding pipelines, and retrieval logic.
* Data Engineers: To build robust, scalable data ingestion pipelines from source systems.
* DevOps/Platform Engineers: To manage the cloud infrastructure, CI/CD for data and code, and monitoring.
* Backend Developers: To build the application-layer API that serves the RAG system.
4. How does this compare to just fine-tuning a model on our data?
They solve different problems.
* RAG is for knowledge injection. It’s ideal when you have a large, rapidly changing body of factual information. It’s easy to update (just add a document to the index) and provides citations.
* Fine-tuning is for behavioral modification. It’s best for teaching a model a specific style, tone, or format, or to learn a new, narrow skill. It’s expensive to re-train and doesn’t easily allow for retracting “bad” information. They are often used together: RAG provides the facts, and a fine-tuned model provides the perfectly formatted response.
5. How do we keep the knowledge base up-to-date in near real-time?
The indexing pipeline should be event-driven. Instead of running a nightly batch job, use webhooks or event triggers (e.g., an S3 ObjectCreated event). When a new file is added to your knowledge source (like SharePoint or a GCS bucket), it should automatically trigger a serverless function that chunks, embeds, and upserts the new information into your vector database. This ensures the RAG system’s knowledge is always current.



![Llama 3 vs Mistral Benchmark: A Data-Driven Analysis [2025]](https://paulscannon.com/wp-content/uploads/2026/01/article_image_1768324461_943-768x419.png)