NVIDIA Blackwell B200: Specs, Price & Performance [Review]
NVIDIA’s Blackwell B200 isn’t just a new GPU; it’s a fundamental shift in how enterprises must architect, budget for, and deploy AI infrastructure. The advertised 20 PetaFLOPS of performance is a headline that grabs the C-Suite, but the 1000W TDP and multi-million dollar system cost is what will break unprepared engineering budgets and data centers. This isn’t an upgrade; it’s a complete platform overhaul that demands a new operational playbook.
Executive Summary
- Think Systems, Not Chips: The true NVIDIA Blackwell product is the GB200 NVL72, a 72-GPU, liquid-cooled, full-rack system. Buying individual B200 GPUs will be a secondary market activity; NVIDIA is selling a pre-integrated AI factory.
- Performance is Specific: The massive performance gains come from new FP4 and FP6 data formats. This dramatically accelerates inference for massive, trillion-parameter models, but the benefit for smaller models or tasks not optimized for these formats is less pronounced.
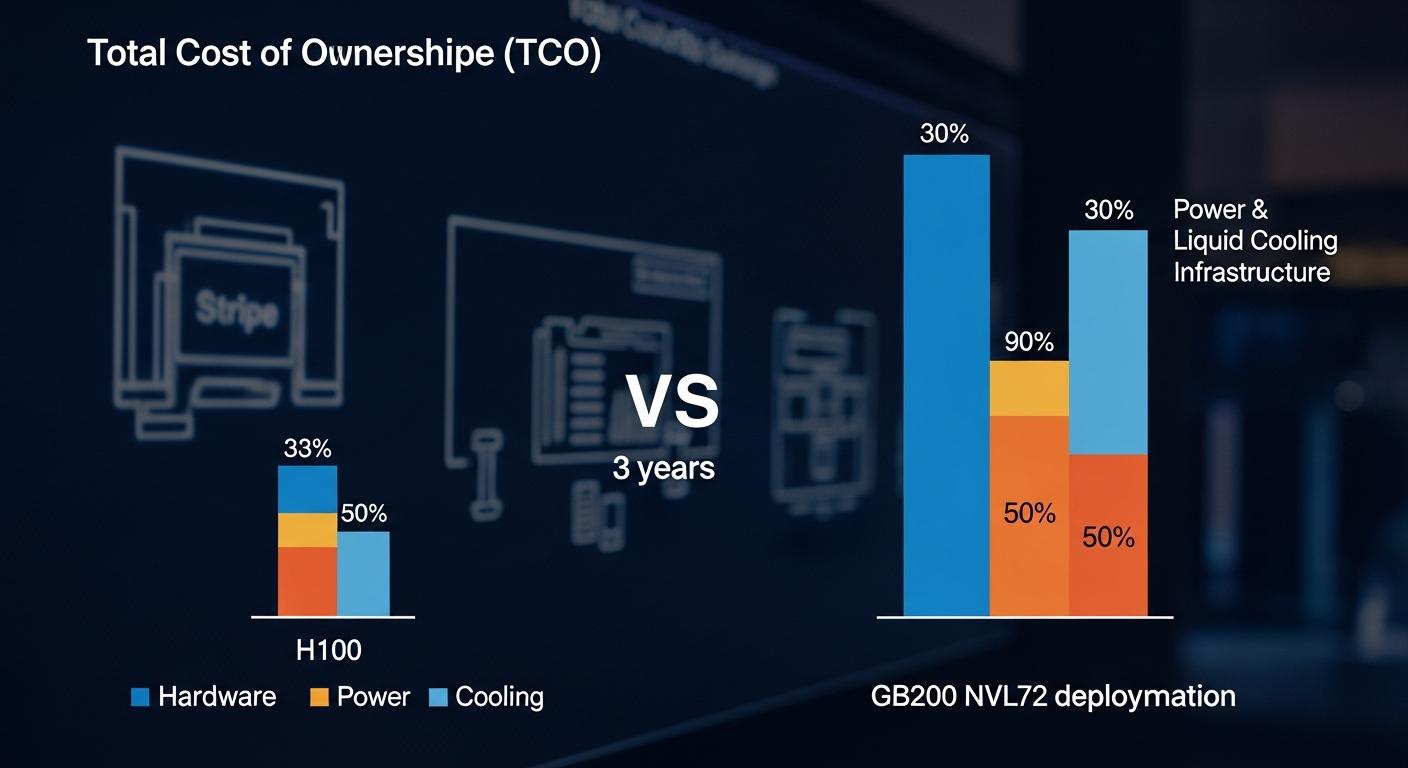
- TCO is the Real Killer: The estimated $30k-$40k sticker price per GPU is just the beginning. The real cost is in the operational expenditure: a single GB200 NVL72 rack can draw 120kW, requiring liquid cooling and a complete rethink of your data center’s power and thermal capacity. For many, this accelerates the need for a clear strategy on how to migrate data centers to the cloud.
- Strategy First, Hardware Second: For 95% of enterprises, the correct entry point to Blackwell is not a purchase order but a cloud instance, like Google’s A4 VMs. On-premise deployment is now a strategic decision on par with building a new data center.
The Business Case: Beyond PetaFLOPS
For the last decade, we’ve been able to approach GPU upgrades incrementally. We’d swap out older cards, maybe upgrade a server chassis or two, and benefit from the generational performance lift. That era is over.
NVIDIA’s strategy with Blackwell, particularly the flagship GB200 NVL72 system, is to sell a complete, vertically integrated solution. It combines 72 B200 GPUs with 36 Grace CPUs, connected by 5th-generation NVLink fabric and Quantum-X800 InfiniBand networking. As detailed by outlets like ServeTheHome, this is not a box of parts; it’s a pre-built supercomputer in a rack.
The business implications are stark:
- Shift from Capex Component to Capex System: You are no longer budgeting for GPUs. You are budgeting for a system that will cost millions of dollars upfront.
- Opex Becomes a Primary Constraint: A 120kW power draw for one rack is astronomical. At an average data center electricity cost of $0.15/kWh, a single GB200 NVL72 rack will cost over $157,000 per year in electricity alone, before factoring in the immense cost of the liquid cooling infrastructure required to dissipate that heat. This is where mastering FinOps for efficient cloud cost management becomes critical when evaluating build vs. buy.
- The “AI Divide” Widens: Hyperscalers (Google, Meta, Microsoft) and sovereign AI initiatives are the primary customers. They are buying these systems by the thousands, creating an extreme supply constraint for everyone else. Access, not just cost, will be a major hurdle.
This is a platform for building foundational models, and understanding what generative AI is and its demands is key. If your business is not doing that, buying a full rack is like using a sledgehammer to crack a nut. The strategic question is no longer “Should we buy the new GPU?” but “At what level of our AI maturity does a Blackwell-class system make financial and operational sense?”
The Architecture: A Pragmatic Breakdown for Leaders
As an operational architect, I look past the marketing numbers to the specs that dictate real-world performance and constraints. Here’s what matters with the NVIDIA Blackwell architecture.
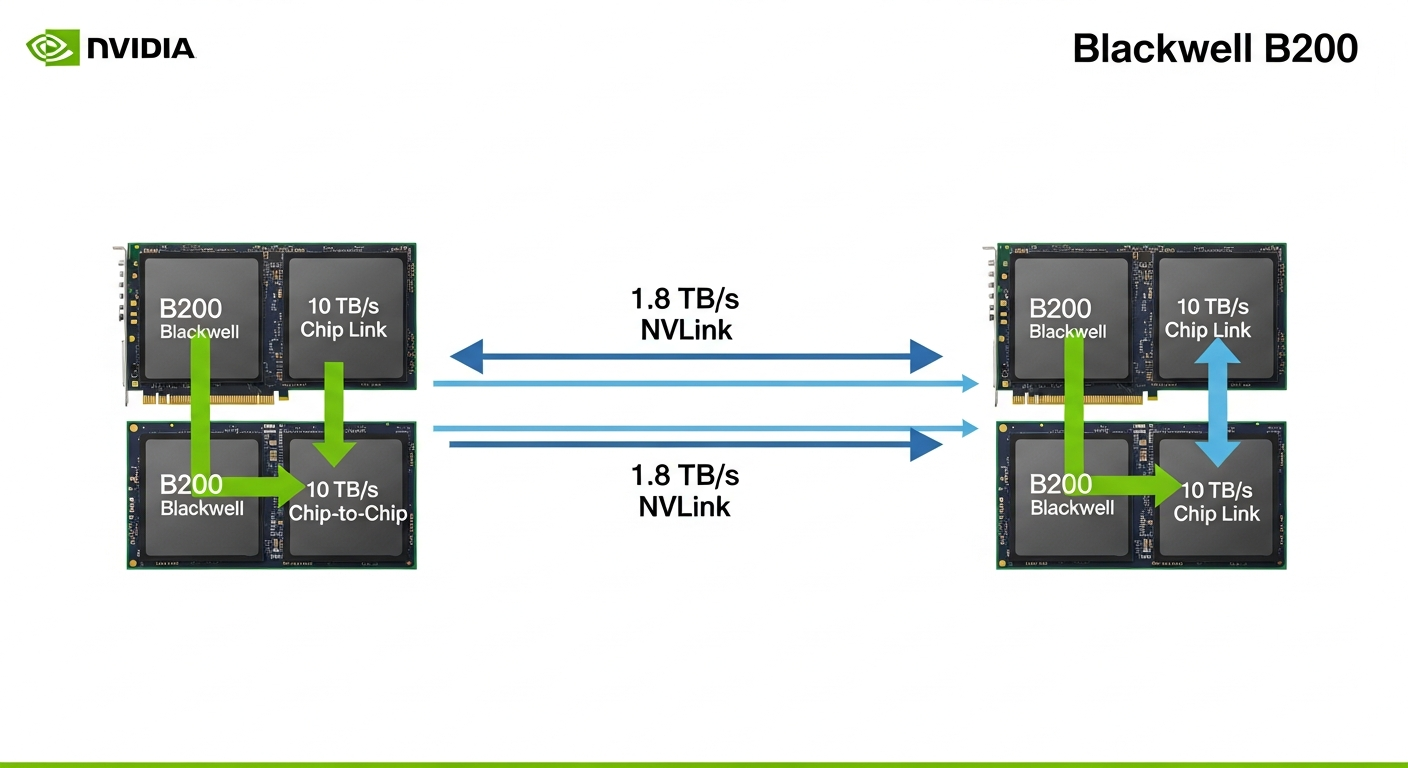
Dual-Die Design & 5th-Gen NVLink
The B200 isn’t one massive chip; it’s two smaller, 104-billion-transistor dies fused together, a feat detailed by AnandTech. This is a brilliant manufacturing feat by TSMC on their 4NP process. But the reason this works is the interconnect. The chip-to-chip link provides 10 TB/s of bandwidth, making the two dies act as one.
More importantly for system scaling, the 5th-generation NVLink provides 1.8 TB/s of bidirectional bandwidth per GPU to the other GPUs in the system.
- Why it Matters: When training a trillion-parameter model, the model itself must be split across multiple GPUs (tensor and pipeline parallelism). The speed of this training is often bottlenecked by the communication speed between GPUs. By doubling the NVLink bandwidth over the H100, NVIDIA directly attacks this bottleneck, making the training of enormous models feasible.
The FP4/FP6 Revolution
This is arguably the most significant innovation for AI inference. Blackwell introduces new, ultra-low-precision 4-bit (FP4) and 6-bit (FP6) floating-point formats, as documented in NVIDIA’s own whitepaper (arXiv:2403.17048).
- Why it Matters: For inference (running a pre-trained model), you often don’t need the high precision of FP16 or even FP8. By using FP4, you can represent the model’s weights with fewer bits. This means:
1. Less Memory: The model takes up less of the expensive 192GB HBM3e memory.
2. Less Bandwidth: Moving those weights from memory to the compute cores requires less bandwidth.
3. Faster Compute: The cores can process these smaller data types much faster.
The result is a claimed 5x inference performance increase over Hopper. For any company serving a large language model to millions of users, this translates directly to lower cost-per-token and reduced latency. However, it requires model quantization and support from the software stack.
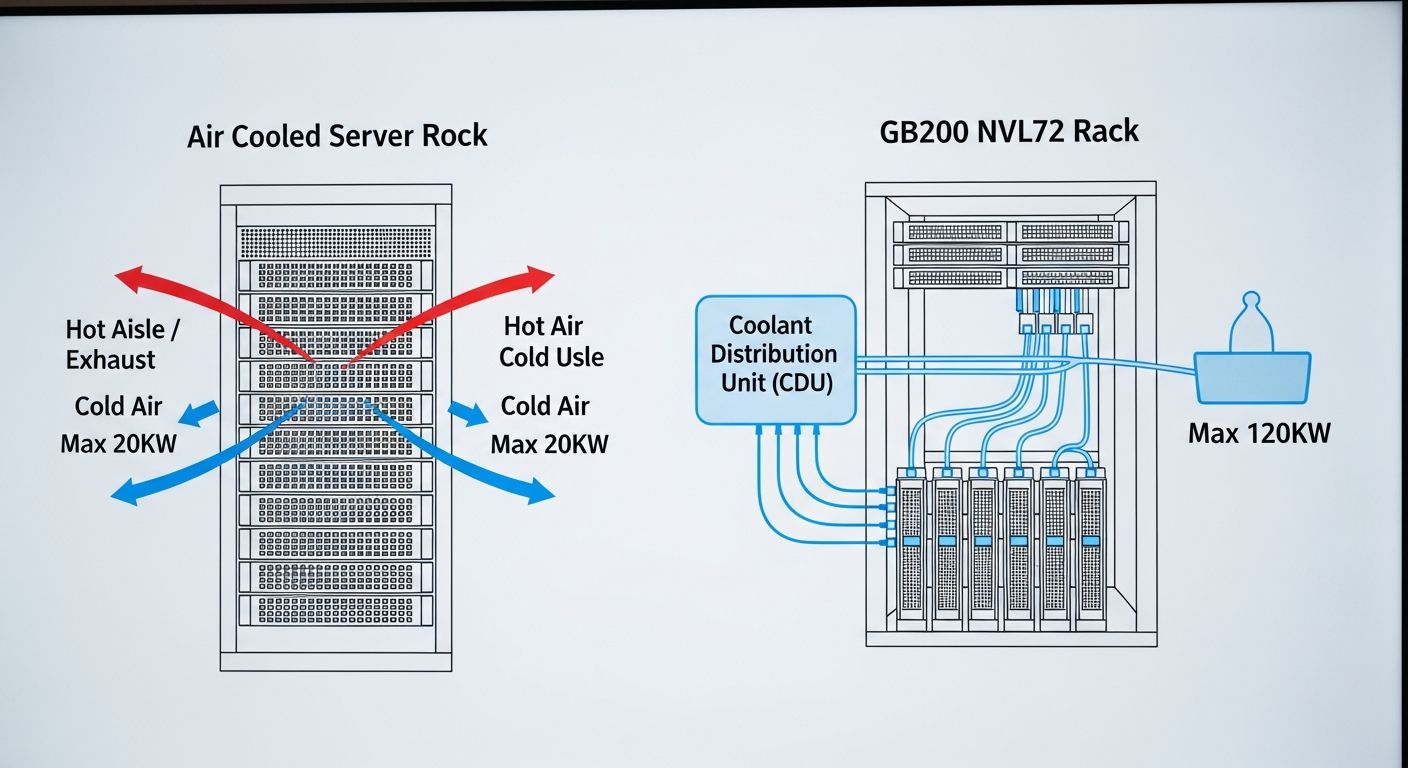
The Elephant in the Room: Power & Cooling
A single B200 GPU has a TDP of up to 1000W, configurable down to 700W. This is a 42% increase over the H100’s 700W TDP.
- Why it Matters: Most enterprise data centers are designed for air-cooled racks drawing 15-20kW. The GB200 NVL72, at 120kW, requires direct-to-chip liquid cooling. This is not a simple upgrade; it’s a facilities-level project involving new plumbing, heat exchangers, and potentially cooling towers. You cannot simply roll a GB200 rack into your existing data center aisle. This physical constraint is the single largest barrier to on-premise adoption for most companies.
Strategic Framework: The Blackwell Adoption Maturity Model
Jumping straight to a full-rack deployment is a recipe for financial disaster. I advise clients to approach NVIDIA Blackwell adoption through a phased maturity model. This aligns investment and complexity with demonstrable business value.
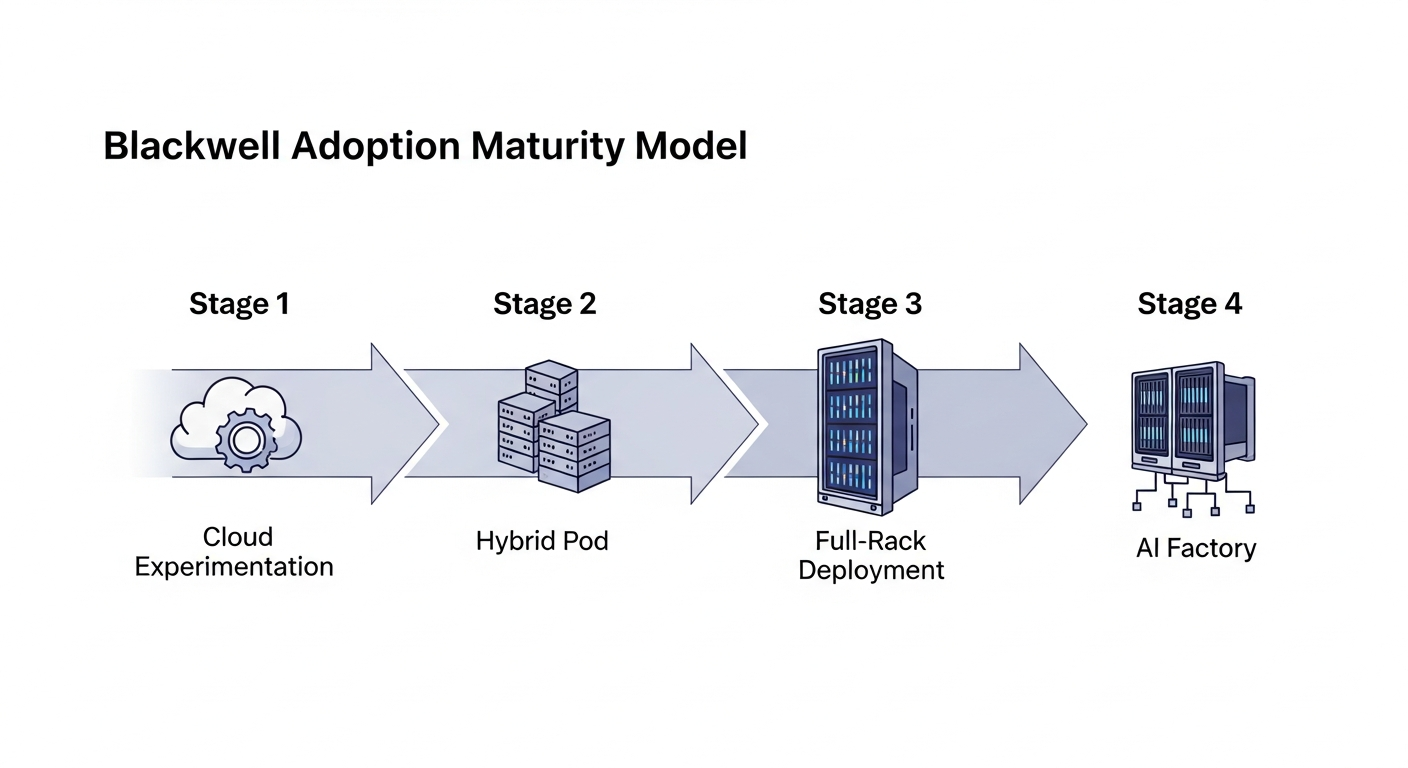
The Blackwell Adoption Maturity Model
| Stage | Description | Key Objective | Primary Challenge |
|---|---|---|---|
| 1. Cloud Experimentation | Renting B200 instances (e.g., Google Cloud A4 VMs) on a per-hour basis. | Validate model performance and ROI on new hardware. | High hourly cost; data gravity and security. |
| 2. Hybrid Pod | Deploying a small on-prem or colo cluster (e.g., 8x B200s in a qualified server). | Fine-tune proprietary models on dedicated hardware. | Significant power/cooling upgrades; network integration. |
| 3. Full-Rack Deployment | Procuring and deploying a complete GB200 NVL72 system. A multi-million dollar Capex project. | Large-scale training of foundational models. | Massive Capex; data center liquid cooling retrofit. |
| 4. AI Factory | Interconnecting multiple GB200 racks to form a massive compute cluster. This is hyperscaler and nation-state territory. | Achieve global AI dominance. | Unprecedented scale, power, and capital. |
Most organizations will live at Stage 1 for the next 12-24 months. The goal is to use the cloud to build the business case that justifies the massive leap to Stage 2 or 3.
Code Implementation: Preparing for Blackwell
Your engineering teams don’t need to wait for hardware to start preparing. The shift to lower-precision formats can be explored programmatically. Here is a “Proof of Work” pseudo-code snippet in a PyTorch-like framework that illustrates the logic an ML engineer would use.
# --- Proof of Work: Conditional Precision with Blackwell ---
import torch
# Assume 'model' is your pre-trained PyTorch model
# Assume 'data' is your input tensor
# 1. Check for Hardware Capabilities
# In a real scenario, this would be a more robust check of the compute capability
has_fp4_support = torch.cuda.get_device_capability(0) >= (10, 0) # Blackwell capability is 10.0
# 2. Define a Quantization Function (Simplified)
# Real libraries like bitsandbytes would handle this
def quantize_to_fp4(tensor):
# This is a placeholder for a complex quantization algorithm
print("Quantizing model weights to FP4 for Blackwell acceleration...")
# ... actual quantization logic ...
return tensor.to(dtype=torch.float4) # Fictional torch.float4 dtype
# 3. Conditionally Apply Lower Precision
if has_fp4_support and torch.cuda.is_available():
print("NVIDIA Blackwell B200 or compatible hardware detected. Applying FP4 quantization.")
model = quantize_to_fp4(model)
model.to('cuda')
else:
print("No FP4 support detected. Running in standard precision (FP16/BF16).")
model.half() # Use standard half-precision
model.to('cuda')
# 4. Run Inference
with torch.no_grad():
output = model(data.to('cuda'))
print("Inference complete.")This demonstrates the core principle: your software must be intelligent enough to recognize and leverage the specific capabilities of the underlying hardware. This is a shift from writing generic CUDA code to writing hardware-aware ML code.

The Retrospective: Hopper vs. Blackwell – A Forced Upgrade?
Comparing Blackwell to Hopper requires looking beyond a simple feature list. It’s a comparison of design philosophies. Hopper was the pinnacle of the incremental GPU era. Blackwell is the beginning of the integrated system era.

| Feature / Metric | NVIDIA B200 (Blackwell) | NVIDIA H100 (Hopper) | Operational Impact |
|---|---|---|---|
| GPU Architecture | Blackwell | Hopper | Generational leap focused on system-level integration. |
| Transistor Count | 208 Billion (2x 104B dies) | 80 Billion | Multi-chip module (MCM) design allows for yields and scale beyond monolithic dies. |
| AI Performance (FP4) | 20 PetaFLOPS (sparsity) | N/A | Game-changer for inference efficiency and cost-per-token. The primary driver of performance claims. |
| AI Performance (FP8) | 10 PetaFLOPS (sparsity) | 4 PetaFLOPS | 2.5x improvement for training/inference tasks already using FP8. |
| HPC Performance (FP64) | 40 TeraFLOPS | 60 TeraFLOPS | A regression. Blackwell is explicitly optimized for AI, not traditional scientific computing. |
| GPU Memory | 192 GB HBM3e | 80 GB HBM3 | Enables larger models to fit on fewer GPUs, reducing communication overhead. |
| Memory Bandwidth | 8 TB/s | 3.35 TB/s | More than double the speed, crucial for feeding the compute-hungry cores. |
| NVLink Bandwidth | 1.8 TB/s (per GPU) | 900 GB/s | Doubles inter-GPU communication, directly accelerating large-scale distributed training. |
| Max TDP | 1000W | 700W | The single biggest operational hurdle. Mandates liquid cooling at scale. |
| Estimated Unit Cost | $30,000 – $40,000 | ~$25,000 – $30,000 | The entry ticket price, dwarfed by the total cost of ownership. |
| Flagship System | GB200 NVL72 (Liquid-Cooled Rack) | DGX SuperPOD (Air-Cooled) | A fundamental shift from selling components to selling fully integrated, opinionated systems. |
NVIDIA Blackwell: Pros & Cons
- Unmatched AI Inference Performance: The new FP4/FP6 data types provide up to a 5x leap for large model inference, directly lowering cost-per-token.
- Massive Memory & Bandwidth: 192 GB of HBM3e memory at 8 TB/s allows for larger, more complex models to fit on a single accelerator.
- Superior Multi-GPU Scaling: The 1.8 TB/s 5th-Gen NVLink is critical for reducing bottlenecks in large-scale distributed training.
- Integrated System Design: The GB200 NVL72 offers a pre-validated, rack-scale solution that simplifies deployment for hyperscalers.
- Extreme Cost & TCO: An estimated $30k-$40k price per GPU is just the start; power and liquid cooling infrastructure costs are astronomical.
- Intense Power & Thermal Demands: A 1000W TDP per GPU and 120kW per rack mandates expensive liquid cooling, a barrier for most data centers.
- Limited Availability: Initial supply will be dominated by hyperscalers, making access difficult for smaller enterprises.
- Reduced HPC Performance: A regression in FP64 performance makes it less suitable for traditional scientific computing workloads compared to Hopper.
The Verdict: NVIDIA Blackwell is not a straightforward “Hopper replacement.” The reduction in FP64 performance is a deliberate design choice, signaling NVIDIA’s laser focus on the trillion-parameter AI training and inference market. This contrasts with other specialized hardware like Google’s TPUs, and it’s worth understanding what a TPU is to see the different design philosophies. For businesses heavily invested in traditional HPC, the H100 or H200 may remain a more balanced choice. For those aiming to be at the bleeding edge of generative AI, Blackwell is the new, non-negotiable standard, provided you can afford the price of admission.
FAQ: Answering the Hard Questions
The Path Forward
The transition to the NVIDIA Blackwell era of AI requires more than a purchase order; it requires an operational blueprint that balances ambition with pragmatism. You must analyze your model pipeline, your data center capabilities, and your financial models before making a move. This is a strategic inflection point for every technology leader.
Planning your AI infrastructure roadmap for the next 36 months? Let’s build a pragmatic plan that bridges your C-Suite’s vision with your engineering reality.





